Introducing PyLighter for Jupyter: PayLead's open-source annotation tool
Pulling essential information is a core need for any data-oriented business. Our team is continuously iterating the robust system we've built, which extracts detailed information from banking transactions such as brands, stores, cities, and countries.

Pulling essential information is a core need for any data-oriented business. Our team is continuously iterating the robust system we've built, which extracts detailed information from banking transactions such as brands, stores, cities, and countries. To accurately pull this information, we designed a model that automatically detects these labels from transactions. The only problem was that it needed annotated data to work to its fullest potential. Another project came to life with that need, and so did Pylighter, Paylead's open-source annotation tool for Named-entity recognition (NER) tasks on Jupyter.
A little bit of context
Most information shared is unstructured. Patterns can't be found in news articles, books, or even in this very blog; the sentence length, the position of verbs, and each word's meaning depend on the formulation of each sentence. Thus, it is challenging for machines to retrieve any information in text, let alone recognize persons from organizations.
However, with the rise of machine learning and natural language processing (NLP), Named-entity recognition technology (NER) has become accessible to data scientists, meaning machines can now accurately tag words in unstructured texts. With NER, tasks across industries with text extraction needs, such as chatbots creating relationship graphs from text, can be automated and turned into action, whether it be scheduling a call with sales or redirecting a client to the appropriate tutorial.
It's evident NER models save precious time anyone would quite frankly rather spend elsewhere. However, the problem with NER tasks is that they usually require an annotated dataset to unleash their full potential, and without it, data scientists are forced to perform the tedious task of labeling a corpus of documents.
This is where PyLighter comes in handy. It brings an annotation tool for NER tasks to the most used platform in data science: Jupyter. It allows data scientists to annotate any corpus of documents with ease in a customizable fashion.
Let's go over what PyLighter can do for data scientists.
Unleashing the power of PyLighter
PyLighter is a free tool that gives users the possibility to go through all the documents in their corpus and annotate them by highlighting groups of letters corresponding to any of their labels. By allowing users to label each character individually, PyLighter helps identify selected characters within a single word or series of connected characters. A prime example of this feature use is in the annotating of root words. In many instances, tagging root words instead of whole words can save time by finding variations of words with similar meanings, such as "actor" or "actress."
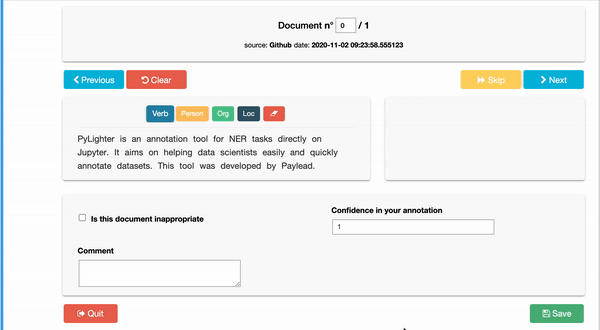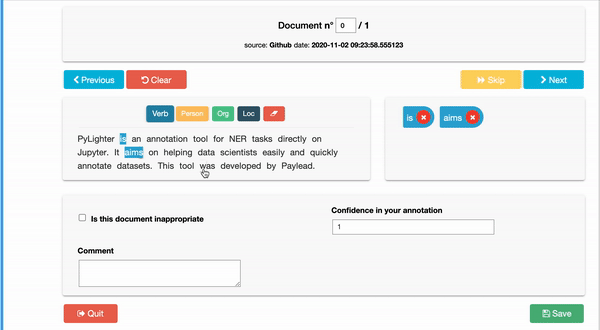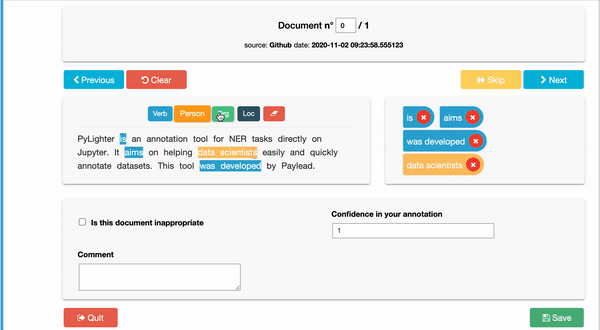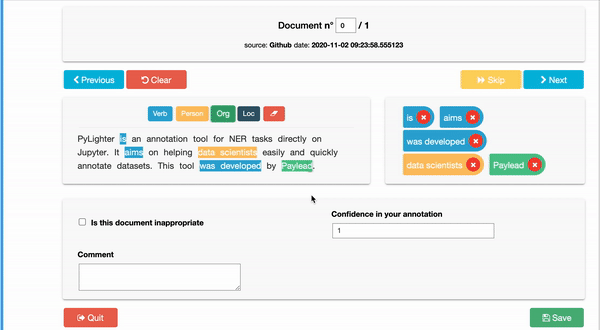
Moreover, when annotating a corpus of documents, there is usually a need for context to tag words or characters properly. For instance, if the task is to highlight inappropriate words in a document to be omitted, knowing the document's source and the intended audience is essential. It would be wrong to leave vulgar words in corporate documents or legal terms in a children's book. This is where PyLighter's ability to add context to documents being labeled shines.
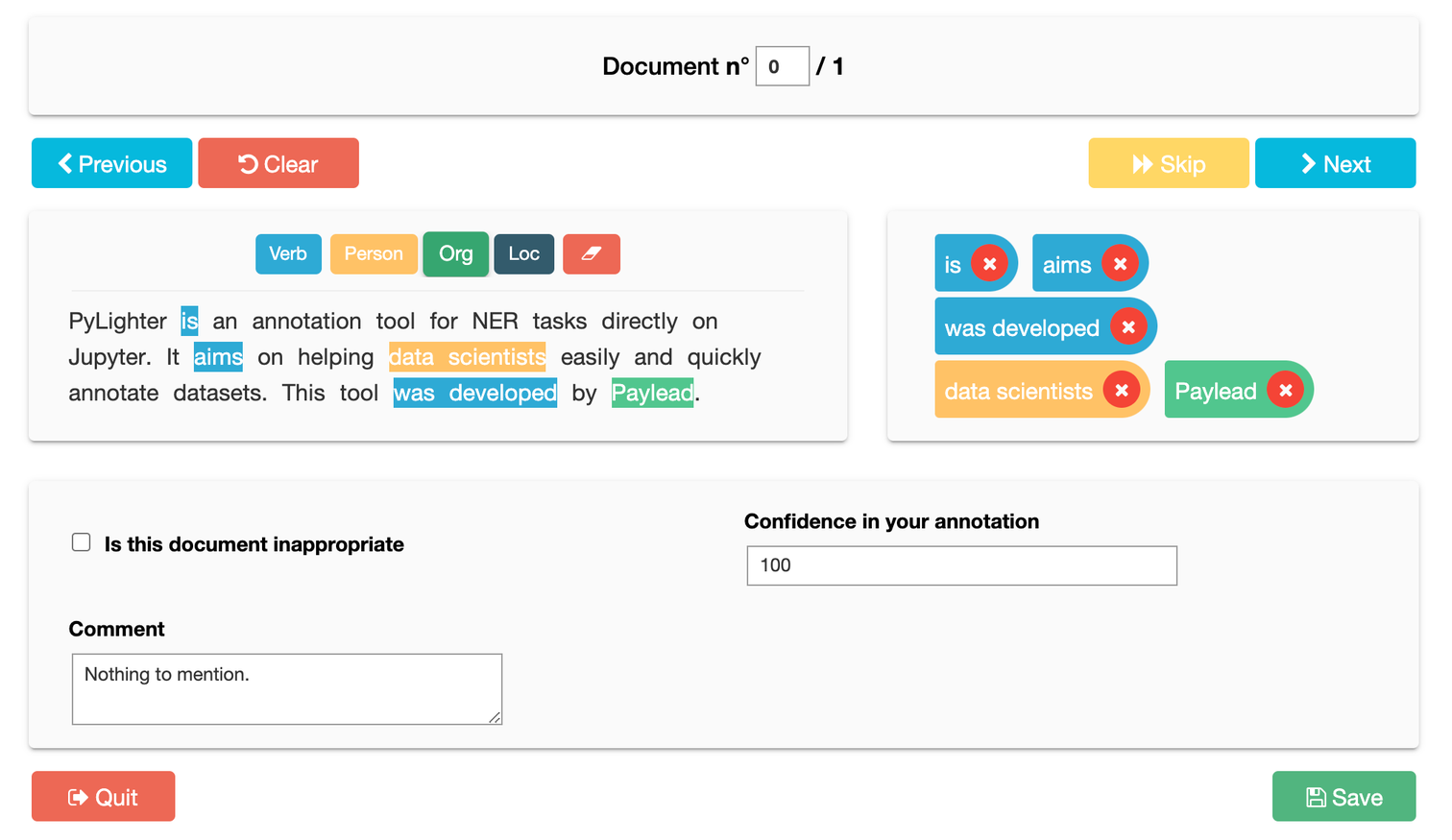
Anyone who has annotated a corpus of documents knows how hard it can be. Eventually, complicated documents come along that seem insurmountable, leaving data scientists unsure of how accurate their annotation is. That's why we've made it possible for users to add a confidence field to grade their annotation by leaving a percentage representing how confident they are in the annotation accuracy.
PyLighter was created to ensure anyone can add any information they see fit to their annotation! That's why we also included the ability to add custom fields. For instance, the image below shows the addition of fields such as the comment, confidence, and appropriate tick box to help with the annotation.
Speeding up your annotation with PyLighter
One of the exciting aspects of PyLighter is that nearly everything is customizable. PyLighter gives users total freedom over font size, space between the characters, selection of colors, and much more. If something isn't optimal for the user, PyLighter most likely offers a customizable setting to meet everyone's needs.
Once the interface has been adjusted, the next thought in anyone's mind is, how do I move faster? As always, PyLighter gives you the possibility to add any keyboard shortcut to any button on the interface. This tool comes in handy for switching between labels, saving time, of course, and, by the way, preserving nerves. Smooth sailing from here on out!
Alternatives to PyLighter
PyLighter is not the first annotation tool for NER tasks. There are plenty of other alternatives, and they all do a great job, providing intuitive interfaces and different features to fit your needs best. However, two of the most common issues with annotation tools are their price and integration into existing infrastructure.
Many of the alternatives to PyLighter require an initial setup and a dedicated server to run on. These requirements pose challenges for small companies who don't have the infrastructure to host servers, correctly secure their data or create data pipelines with an annotation tool. This task becomes nearly insurmountable when there are no data engineers in the company.
So most alternatives only suit large companies, leaving small ones in the same predicament. This is where PyLighter comes in. PyLighter does not require any setup or installation of any kind. Moreover, data scientists don't need to set up a pipeline. PyLighter is built for use in Jupyter, giving data scientists the ability to freely manage their data and quickly use their freshly annotated data to train their machine learning models.
PyLighter was an excellent help for the data scientists at Paylead, allowing them to annotate data sets in a blink of an eye. We genuinely hope that it can do the same for you. You can find more information on our GitHub page where you can learn more and starting Pylighter in minutes: https://github.com/PayLead/PyLighter